

Sieć społecznościowa z dokumentów historycznych dzięki metodzie NER
Sieć społecznościowa z dokumentów historycznych dzięki metodzie NER
Dlaczego ograniczać badania źródłowe wyłącznie do tekstów, które zdąży się przeczytać?

Praktyka administracji kolonialnym imperium Portugalii (XVI-XIX w.) to temat, który badać można rysując sieć powiązań między najważniejszymi urzędnikami. Centrala w Lizbonie i administratorzy w Angoli, na Wyspach Zielonego Przylądka, w Gwinei, na Wyspach Świętego Tomasza i Książęcej i oczywiście w Brazylii wymieniali listy i dokumenty, które zachowały się w Arquivo Histórico Ultramarino. Zebranie informacji o kierunkach i intensywności tej wymiany może powiedzieć wiele o relacjach między metropolią i koloniami, jednak wymaga lektury ogromnej liczby tekstów: dla okresu między powołaniem Rady Zamorskiej w Lizbonie (1642) a ogłoszeniem niepodległości Brazylii (1822) to prawie 170 tys. dokumentów. Wydaje się, że w takiej sytuacji należy po prostu ograniczyć zasięg badania, skrócić analizowany okres lub skoncentrować się na relacjach między najważniejszymi koloniami i urzędnikami.
170 TYS. DOKUMENTÓW
Agata Błoch, Demival Vasques Filho i MichałBojanowski w opublikowanym na jesieni zeszłego roku artykule Networks from archives: Reconstructing networks of official correspondence in the early modern Portuguese empire (https://doi.org/10.1016/j.socnet.2020.08.008) dowodzą, że zakres badań historycznych nie musi być ograniczany ludzką percepcją. W swoim badaniu skorzystali oni z prawie 170 tys. zdigitalizowanych i transkrybowanych dokumentów z Arquivo Histórico Ultramarino i dzięki czytaniu maszynowemu przygotowali zestaw danych historycznych. Pozwolił on wykazać zmiany w sieci powiązań administracyjnych imperium w okresach władzy kolejnych królów Portugalii. O ile analizy sieciowe nie są w historiografii niczym nowym, “[…] required amount of traditional archival work makes historical network studies usually small-scaled“ - zauważają już na wstępie autorzy tekstu. Wykorzystanie czytania maszynowego pozwala zbudować sieć pełnej wielkości, bazującą na wszystkich dostępnych źródłach.
Jak przebiegało to badanie?
korzystano z gotowych już transkrypcji prawie 170 tys. skanów;
losowe transkrypcje anotowano, oznaczając istotne z punktu widzenia badania słowa i frazy - tak powstała próba zawierająca 4230 anotowane dokumenty;
teksty z próby stały się zasobem pozwalającym na wyuczenie i przetestowanie modelu NER (Named Entity Recognition - rozpoznawania znaczeń, więcej o tym niżej). Zadaniem modelu było automatyczne oznaczanie nadawcy i odbiorcy oraz pewnych atrybutów dokumentu. Model ten zastosowano następnie do automatycznego przetworzenia wszystkich dokumentów;
z wykorzystaniem wyrażeń regularnych (języka pozwalającego na wyróżnianie pewnych wzorców w tekście) wygenerowano równolegle podstawowe metadane dokumentów oraz kluczowe frazy;
zastosowanie obu metod pozwoliło na stworzenie bazy danych;
baza danych umożliwiła wygenerowanie sieci relacji, którą następnie można było poddać analizie.
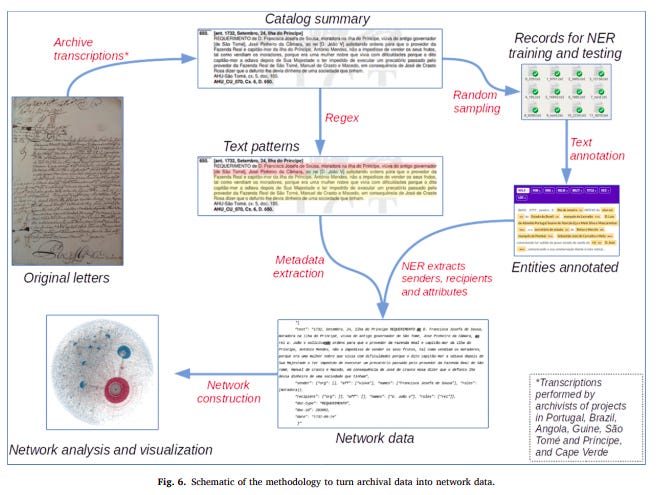
Przygotowanie bazy danych polegało na zastosowaniu dwóch metod pracy z tekstami dokumentów: wyrażenia regularne zastosowano do tych fragmentów tekstów, których struktura była w pewnym stopniu powtarzalna, a NER - do wyróżniania tych fragmentów, których nie dałoby się złapać w ten sposób. Jak działają obie te metody?
WYRAŻENIA REGULARNE I NER
Weźmy przykładowe zdanie z zupełnie innej beczki:
W 1308 roku Krzyżacy spalili Gdańsk.
Wyrażenia regularne pozwolą nam w prosty sposób ująć daty zapisywane bezpośrednio cyframi (tutaj mamy datę w postaci RRRR, ale nikt nie powiedział, że jesteśmy ograniczeni wyłącznie do tego formatu). Jeśli mielibyśmy do czynienia z tekstem współczesnym i narracją podręcznikową, to bez trudu rozpoznalibyśmy także daty dzienne i wieki. Zamieńmy datę na ciąg znaków i szukajmy dalej:
W [RRRR] roku Krzyżacy spalili Gdańsk.
Bulla papieska Aleksandra IV przyznała miastu – od roku [RRRR] – prawo organizowania dorocznych jarmarków św. Dominika.
W [RRRR] rada Gdańska postanowiła uznać władzę Władysława Jagiełły.
Jak jednak oznaczać w tekście znaczenia, które nie mają tak jednorodnego schematu? Bez trudu wyznaczymy daty roczne, ale co z nazwami własnymi? Oczywiście możemy zrobić słownik i przez niego wyszukiwać nazwy miejsc i nazwiska - ale to działanie efektywne tylko na krótką metę, nie da się go zastosować do 170 tys. dokumentów, bo każdy z nich należałoby przeczytać w poszukiwaniu unikalnych nazw własnych (powodzenia).
Stwórzmy sobie kategorie (znaczenia), które będą nas interesować. Niech to będą miejsca i instytucje (organizacje). Jeśli zastosujemy wybrane narzędzie NER, nasze zdanie zostanie przetworzone w taki sposób:
W 1308 roku [Krzyżacy = ORGANIZACJA] spalili [Gdańsk = MIEJSCE].
NER nie będzie tego oczywiście wiedział sam z siebie, a pewność przypisania nie musi wynosić 100 proc, szczególnie kiedy mamy do czynienia z bardziej skomplikowanymi frazami.
W 1410 [rada Gdańska = ORGANIZACJA 70%] postanowiła uznać władzę [Władysława Jagiełły = ORGANIZACJA 10%].
Jak widać, dużo zależy tutaj od predefiniowanych kategorii. Gdybyśmy wyznaczyli kategorię OSOBY, Jagiełło miałby szansę na pewne przypisanie - ponieważ tego nie zrobiliśmy, NER oszacował go jako ORGANIZACJĘ, ale tylko na 10 proc. To oczywiście przykład bez żadnych obliczeń.
Udostępniane przez konsorcjum CLARIN-PL narzędzie NER poprawnie rozpoznało nazwy własne (każdy może spróbować zrobić taki eksperyment):

Program wyznaczył nam trzy kategorie nazw własnych: nam_liv (Jagiełło), nam_org (Krzyżacy) i nam_loc (Gdańsk) oraz bez problemu poradził sobie z odmianą (Gdańska / Gdańsk). Nie informuje jednak o stopniu pewności, oznaczając poszczególne słowa z tekstem w sposób binarny:
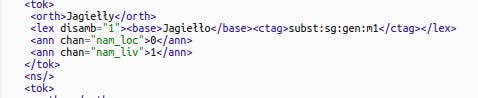
Model wykorzystywany w NER konsorcjum CLARIN-PL działa dzięki danym z Narodowego Korpusu Języka Polskiego - możemy wybrać rozpoznawanie dla języka współczesnego i języka XIX-wiecznego. Jeśli chcemy badać język starszy, poziom pewności może być dużo niższy.
PRAKTYKA NER
Autorzy badania dokumentów kolonialnych również skorzystali z ogólnodostępnego modelu NER dla języka portugalskiego. Jak piszą, jego dokładność wynosi około 89 proc., jednak jest zdecydowanie niższa dla tekstów sprzed XIX wieku. Z tego powodu postanowili wytrenować własny model NER z wspomnianej już przeze mnie próby 4230 dokumentów z przygotowanymi ręcznie anotacjami - w efekcie przeprowadzonych testów okazało się, że dokładność modelu wynosi 93.1 proc.
Jak działa algorytm NER? W wielkim skrócie: najpierw wyodrębnia zdania i słowa, taguje je, wyznaczając cechy gramatyczne. Następnie, korzystając z danych treningowych (takich jak np. NJKP) proponuje zestaw interpretacji i wylicza najbardziej prawdopodobną. Metoda przypisania klasyfikacji do rozpoznawanego słowa (tokenu) może brać pod uwagę także strukturę zdania i inne cechy. Niektóre modele NER są bardzo zaawansowane. W popularnym dla języka angielskiego modelu nazywanym BERT (Bidirectional Encoder Representations from Transformers), trenowanym m.in. na Wikipedii (2.8 miliarda słów) i BooksCorpus (800 mln słów), brane pod uwagę jest całe zdanie (w odróżnieniu od innych modeli, które “czytają” od lewej do prawej i nie “znają” wszystkich słów ze zdania podczas określania cech kolejnych z nich.
Nie mam ambicji rozumienia obliczeń statystycznych prowadzonych w ramach określonego modelu NER oraz znajomości poszczególnych etapów procesu wyznaczania nazw własnych (czy też “ról semantycznych“). Nie jest to niezbędne do zrozumienia, w jaki sposób wykorzystać można modele NER i jakie wiążą się z tym ryzyka. Proces generowania danych opisany w Networks from archives: Reconstructing networks of official correspondence in the early modern Portuguese empire to dobry przykład metody przekraczania ograniczeń ludzkiej percepcji w badaniu historycznym.
Podsumujmy:
NER pozwala na zdecydowane zwiększenie liczby źródeł poddawanych analizie;
ogólny model NER dla danego języka może nie być odpowiednio efektywny, szczególnie jeśli pracujemy na dokumentach sprzed XIX wieku. Należy wówczas wytrenować własny model na bazie ręcznie anotowanych dokumentów;
skuteczne rozpoznawanie NER wymaga odpowiedniego przepracowania kategorii semantycznych (zob. s. 7 w cytowanym artykule);
NER może być skomplikowaną metodą, ale dostępne są modele i narzędzia, które można z powodzeniem zastosować - albo samodzielnie kodując program do rozpoznawania znaczeń (w Pythonie czy R), albo korzystając z usług takich jak te udostępniane przez CLARIN-PL (do czego zachęcam);
maszynowe przepracowywanie źródeł tekstowych możemy wspomóc także zastosowaniem wyrażeń regularnych.
PRZECZYTAJ NA HISTORIAIMEDIA.ORG
Dobra alternatywa dla Google Scholar: open source i z API
25 milionów artykułów naukowych indeksuje baza Internet Archive Scholar. Wszystkie artykuły opublikowane online są dodatkowo zarchiwizowane w Wayback Machine. Metadane artykułów pochodzą z otwartej i współedytowanej przez użytkowników bazy fatcat.wiki. Z Internet Archive Scholar korzystać można także za pomocą interfejsu maszynowego: pozwala to nie tylko na budowę własnych wyszukiwarek, ale też prowadzenie badań publikowania naukowego. To ostatnie jest bardzo utrudnione, jeśli chcemy korzystać z Google Scholar - serwis ten nie pozwala na łatwe pobieranie danych o publikacjach i cytowaniach.
I ty karmisz sztuczną inteligencję
Jakub Wątor pisze o ludzkiej pracy, będącej podstawą rozwiązań AI. W artykule m.in. Amazon Mechanical Turk i CAPTCHA, ale też interesujące przykłady badań prowadzonych przez badaczy i badaczki z Polski.
Pierwszy tweet (2006) na sprzedaż
Założyciel Twittera Jack Dorsey sprzedaje prawa do pierwszego tweeta, opublikowanego w marcu 2006 roku. Tweet oferowany jest na platformie Valuables, a jego kupno oznacza przyznanie unikalnego cyfrowego certyfikatu. Valuables to giełda takich certfikatów, pobierająca prowizję od sprzedaży. Swoje Tweety oferuje też m.in. Elon Musk.
Zapraszam na HistoriaiMedia.org oraz do polecania tego newslettera znajomym. Obecnie subskrybuje go 9 osób.
To, co wyczyniają media społecznościowe, a w szczególnie Facebook, jest dalekosiężne i katastrofalne w skutkach, których większość użytkowników nie pojmuje. Dobrze, że przedstawiasz szerszy kontekst.